creating wikidata items in batch: the Portuguese local elections example
Every four years there are new local elections in Portugal - the next will be in a couple of months. For a new Portuguese local election event there should be a new wikidata item... only these election events actually have distinct (municipal) local elections, 308 of them. That means, the local election item has (or should have) 308 parts. How to create them?
This is what I did for the 2025 elections. It's quite probably not the best way to do this, but it got the task done:
- I created a query looking at the parts of the 2021 elections. I saved the output and changed the names, replacing 2021 to 2025 - and that gave me a list of all the new items I had to create;
- I took the list of items names and turned it into a quickstatements csv file - not only stating the names of the items I wanted to create, but also adding a very basic set of properties to them. I ran it through the online tool, 308 items were created;
- I made a new query to have a list of these 308 items that were created, and saved its output because we now need to add them as parts of the 2025 elections item;
- created that new quickstatements csv saying that the 2025 elections had as a part each of those new items, and ran it.
PS: I did this, possibly better, for the 2021 elections. I should have documented what I did but I didn't do it, and for 2025 at the begining I didn't even recall that I had been the one doing it for 2021. So, this blog post will hopefully help me know what I will need to do in 2029... but I hope it might also be useful to others, for similar tasks.
tags: wikidata, bulk, quickstatements, tutorial, en
musical endeavours
It has come to my attention that "my worlds don't cross" - many people who know me for some activities have no idea I delve in anothers. In particular, plenty of people don't know I'm a musician.
Of course, it is quite probable that those also don't read this blog (who does?), but in any case, I felt compelled to write this short blog post to talk about two of musical projects - and how can you support me by adding their albums to your collection.
My main focus for more than a decade has been on kokori, a post-cyberpunk industrial duo that you can sample on this youtube playlist that showcases several songs from our full-length album 'rootkit' - an album that you can buy on CD.
A distinct project is Qink, and Qink is not kokori. Instead, it is meant to be "the final inorganic ambient to your darkest needs", the soundtrack to your horror show. You can listen to its album or even purchase its cassette tape edition.
tags: music, kokori, qink, rootkit, en
escape commands for ssh
Apparently this isn't as well known as it (IMO) should, so... here it is:
There are escape sequences on SSH, ie., if you are running an ssh session, you can control it by sending commands to it.
Useful commands:
~. - terminate connection (and any multiplexed sessions) ~B - send a BREAK to the remote system ~C - open a command line ~R - request rekey ~V/v - decrease/increase verbosity (LogLevel) ~^Z - suspend ssh ~# - list forwarded connections ~& - background ssh (when waiting for connections to terminate) ~? - this message ~~ - send the escape character by typing it twice (Note that escapes are only recognized immediately after newline.)
MiniDebConf Portugal 2023
![]()
I've been a Debian user for a long time, but I've always sought (and felt the lack of) some sort of impulse to be more involved with Debian. Part of it, I suppose, was the lack of someone 'closer' (not necessarily, but also physically close) following the same path, or pushing in the same direction... Anyway, once in a while I did find some opportunities to do something about it: in 2008 I helped organize Tecnonov 2008 where not only we had a Debian Developer talking about the project, we also had a key-signing party (and I got my now expired key signed by the DD in question). The year later, I went to Aveiro for Debian Day PT 2009, but... well, that was so long ago that the t-shirt I've got there has already been recycled!
It was thanks to Ubucon Europe 2019 in Sintra that I've learned for the first time that there was an ongoing attempt to being DebianDay to Portugal... and finally, in 2023, a "local test" is being organized, a MiniDebConf in Lisbon that will, hopefully, also serve as a step towards a future DebConf in Portugal.
I have to confess, the younger me of ten, or the even younger me of twenty years ago would be a lot more excited with this, but still, it is finally happening, so how could I not attend? So here I am: with time off taken from work, hotel room reserved, ready for a week of Debian (and more generically free software) along likeminded individuals. I've even decided to contribute more actively and give a talk and a workshop...
It starts already this sunday, and it lasts until thursday. See you there?
tags: debian, debianday, tecnonov, minidebconf, lisbon, aveiro, debconf, events, portugal, ubucon, talk, workshop, Free-Software, en
How to scp with a jump host
The syntax isn't the most intuitive, I'm afraid.
If you want to scp files from a remote machine into yours, or vice versa, and you only have access to the remote machine via a jump host...
ie, if you need to
ssh -J jumphost:port remotehost
then, to copy files from remotehost to your local machine, you can do it by doing
scp -oProxyCommand="ssh -W %h:%p jumphost -p port" remotehost:/path .
Merankorii Live at Club Tidal's Night Stream

Celebrating the shortest?/longest? night (depending on where you are in the world), this year's Club Tidal solsice party is going to be a 24 hours festival, and my solo musical project Merankorii is going to participate by playing Cycle #35 (if you're in Portugal, that will be at 21:20, on December 21).
As some of you know, Yule is when my birthday also is, so this is a special celebration for me...
This online festival is going to be live streamed, so make sure to tune in during this 24h period and celebrate the Solstice by witnessing to people from all over the world livecoding sounds for your pleasure!
tags: Merankorii, live, music, tidalcycles, algorave, concert, en
Happy 20th birthday, ANSOL!
Today we celebrated the 20th anniversary of ANSOL, the Portuguese Free Software Association. It has been an honor to be part of the history of this still young association, and here's hope for an active 20 years more - I'll gladly celebrate its 40th!
In these past 20 years, ANSOL worked on many issues, but if I had to highlight 3, I'd point out:
- the fight against Software Patents in Europe - which stopped (or stalled?) software patents;
- the Open Standards Law in Portugal - ahead of the curve;
- the Portuguese anti-DRM law.
But there are many more challenges ahead... and our victories aren't closed books.
- The Unified Patent Court in Europe is about to become a reality, and with it Software Patents;
- The Open Standards Law in Portugal exists, but in practice it is isn't being actually applied;
- And while we have a good protection against DRM in law (as far as we can within the EU, thanks to InfoSoc), there is now a covert attempt to water it down.
So, what now? Well, there is plenty to do: we should ensure we don't loose the Freedoms we have achieved, and we should strive to get those we still didn't get.
There is plenty more to do, and you can help.
If you're in Portugal, join ANSOL. If you're in Europe, FSFE will appreciate your contribution. If you're in Latin America, here's your link. In India, join here. Based in North America, with worldwide mission, there's FSF.
Of course, as we could see in those who have joined ANSOL in today's celebration, there is plenty beyond the realm of software. Consider getting to know Wikimedia Portugal or the Wikimedia Foundation, Direitos Digitais in Portugal and EDRI in Europe or EFF overseas.
Let's shape the future, together.
tags: ANSOL, Free-Software, Digital-Rights, en
Are Cassette tapes dead? (again)
Tired of reading people saying that one or another mature technology was dead, ten years ago I decided to act upon one of those claims (saying that cassette tapes were dead) and write a blog post, where, using the data available on Discogs, I made a graph showing the percentage of cassette releases related to all of the releases on that database.
That blog post had more success than I thought would have, with some people, once in a while, wondering how were things progressing (not only regarding the cassette tapes market on current days, but also the growth of discogs' database and its knowledge of past releases). I did update the graph a few times since the initial blog post, but today, to mark the 10th anniversary of the initial post, I decided to actually write a script that automatically generates such a graphic, and generate one of those graphs, once again.
And, guess what!, turns out cassette tapes aren't dead, or even dying.
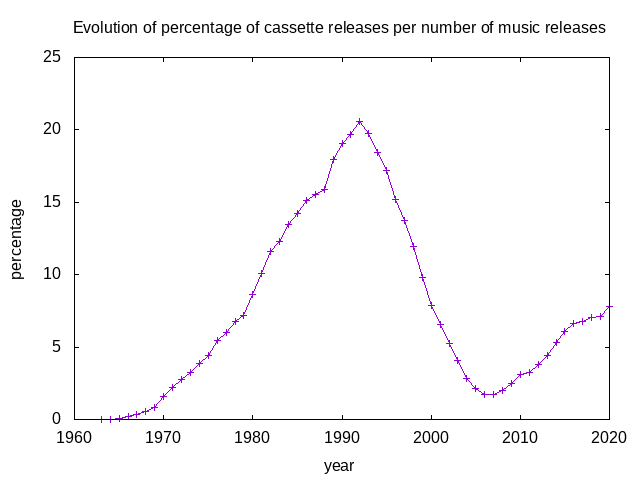
tags: discogs, stats, cassette, tape, compact cassette, music, data, software, music business, music market, en
repo: using a local manifest
One of the useful and rarely mentioned configurations of repo is the use of local manifests.
See, repo is a powerful tool when you need to deal with a project that uses
several git repositories at the same time, and those are controled by a
manifest file. However, on your local development environment, you will often
want to extend or change something on the environment described on the
manifest, either by removing, adding or more often replacing one of the entries
with a slightly different configuration.
You can do that by using a local manifest, that will be applied on the top of the other manifest files. The CyanogenMod project used to have a pretty nice documentation about this, but that's one of the contents that were not migrated into Lineage OS's wiki, so I decided to make this blog post, reproducing the old wiki's content.
The local manifest
Creating a local manifest allows you to customize the list of repositories
used in your copy of the source code by overriding or supplementing the default
manifest. In this way, you can add, remove, or replace source code in the
official manifest with your own. By including repositories (which need not even
reside on GitHub) in a local manifest, you can continue to synchronize with the
repo sync command just as you would have previously. Only now, both the
official repositories from the default manifest and the additional repositories
you specify will be checked for updates.
Adding and replacing repositories
To add to the contents of the default manifest, create a folder called
local_manifests under the .repo directory, then create an XML file (text
file with .xml extension) inside that directory. You can call the XML file
anything you like, as long as it ends in .xml. The default however is
roomservice.xml. Also, you can create separate XML files for different groups
of repositories. e.g. mako.xml for Google Nexus 4 related repositories and
cat-eater.xml for an unofficial device on which you're working.
Let's start with an example which we can use to describe the syntax:
<?xml version="1.0" encoding="UTF-8"?>
<manifest>
<remote name="omap" fetch="git://git.omapzoom.org/" />
<remove-project name="CyanogenMod/android_hardware_ti_omap3" />
<project path="hardware/ti/omap3" name="platform/hardware/ti/omap3" remote="omap" revision="jb-dev"/>
</manifest>
The first line containing <?xml version="1.0" encoding="UTF-8"?> is a
standard XML declaration, telling interpreters this is an eXtensible Markup
Language file. Once this is established, the <manifest> and </manifest>
tags enclose some contents which the repo command will recognize.
First, a remote for git is declared and given the name "omap". In git, a
remote essentially refers to a place and method for accessing a git repository.
In this case, omapzoom.org is a site that contains special up-to-date
repositories for Texas Instrument's OMAP platform. This is equivalent to the
following git command:
git remote add omap git://git.omapzoom.org/
The next line removes a project (specifically,
cyanogenmod/android_hardware_ti_omap3) declared in the default manifest.
After running repo sync, it will no longer be available in the source tree.
The next line defines a new project. In this case, it replaces the removed
project android_hardware_ti_omap3 with one from Texas Instruments, using the
"omap" remote that was defined above.
When adding a new project that replaces an existing project, you should always remove that project before defining the replacement. However, not every new project need replace an existing cyanogenmod project. You can simply add a new project to the source code, such as when you want to add your own app to the build.
Note that when adding new projects, there are at least three parts defined:
- remote -- the name of the remote. this can be one that was defined in either the default
manifestorlocal_manifest.xml. - name -- the name of the git project-- for github it has the format
account_name/project_name. - path -- where the git repository should go in your local copy of the source code.
- revision -- (optional) which branch or tag to use in the repository. If this attribute is omitted,
repo syncwill use the revision specified by the<default ... />tag in the default manifest.
After creating .repo/local_manifests/your_file.xml, you should be able to
repo sync and the source code will be updated accordingly.
Note: You can use local repositories in the manifest by creating a remote
that points to file:///path/to/source. For example: <remote
name="local-omap" fetch="file:///home/username/myomap" />
License
All textual content of the CyanogenMod Wiki was released under the Creative Commons Attribution-Share Alike 3.0 Unported license (CC-BY-SA), and so this blog post should be considered licensed under the same terms.
tags: repo, manifest, local-manifest, local_manifests, git, en
Decentralized Privacy-Preserving Proximity Tracing -- is it really?
DP-3T, as it is known, stands for Decentralized Privacy-Preserving Proximity Tracing. It tries to be a decentralized, privacy-preserving solution to a problem: to make phone applications help mitigate the current COVID-19 pandemic.
OK, let me take a step back. There have been talks (and in some contries already actions) about having an app to use phones in order to help track down the spread of COVID-19. I am not focused, in this article, to argue that the idea, in general is bad (tip: I think it is, due to privacy concerns), or to point out that relying on big companies like Google or Apple to "take care of it" using closed and opaque methods is a really bad idea (tip: it should be obvious: it is). I also don't plan to discuss what is each country proposing, adopting, or doing: not even the Portuguese case, where the Prime Minister and President announce they are against geolocalization, one week later the same Prime Minister consider it a possible solution, and one other week later the adoption of a platform for that is announced. I am not even focused on the discussion between the adoption of DP-3T or one of the proposals of PEPP-PT: much was already written about it, and if you still don't know that DP-3T is a better design than any of the PEPP-PT endorsed solutions.
Instead, this article is about something I didn't see yet anything making the case for: DP-3T, the best protocol/architecture for a solution out there, claims to be Privacy-Preserving. But is it?
Not yet
My first take on this issue is to consider DP-3T as it is right now. It is, we understand, an ever-evolving specification, that, due to the time constraints inherent to the demand for applications of this sort, need to adopt a 'release early, release often' approach. Still, in the moment I am writting this, there are 14 open issues to the spec tagged as 'privacy risks'. Privacy, like security, or life, in certain cases is quite binary: there only needs to be one privacy issue with a certain protocol, format or tool, to make it not be privacy-preserving, so the answer to the question of DP-3T is privacy perserving is... "not yet."
Not really
But is that it? If you take a closer look, things get even grimmer. From the "privacy risk" issues previously opened and now closed on the project, we can see that several of them (nine, at this moment) were closed because they stopped having input. While a manual reading of each of them will show a status of them, and most of them were dealt (partially or entirely) one way or another, the struggle of the maintainers of the project to keep the number of issues low is clear, the reference to future versions of the documents leave things unclear of wether the issues have been addressed or not, and the way some things are not solved, but only mitigated shows that there is a "best effort" sort of approach to privacy, the idea that "let's see how privacy-preserving can we be in a rushing development cycle", instead of what it should be: a firm stance that no privacy-risk can exist in a privacy-preserving solution.
I do understand that the critic here so far is vague enough that one could argue that we're still on the 'not yet' field: after all, after all the privacy-related issues are closed, after all the documents still being prepared are published, one can go through all of those issues, check the latest version of the document, and verify if all of the privacy issues were indeed solved. Arguably, they could. But we do not need to stay on the theoretical field here, not when the "best effort" approach, even in partial sacrifice of privacy, is actually documented. My favorite example of this, is the FAQ's 5th point, about the use of anonymous communication systems.
Why not use mixnets or other anonymous communication systems to query the server?
In the answer to this question, DP-3T stipulates, first, that this is a valid question and concern. Then, they explain that they decided not to for three reasons: a solution would increase complexity, anonymity would cost latency and bandwidth, and it would widen the field of research necessary to take protocol decisions.
In the end, the answer is a claim that there currently is no system ready to use DP-3T could piggy back on and simply use to this purpose, mature enough to the scale DP-3T aims to be deployed -- if there was, they'd use it.
While I do not disagree - such anonymous communication system is a need we, as a society, have for a long time, but an itch we did never focus on scratching, and the solutions so far are far from a stable and consolidated state - I also believe that this is clear proof that DP-3T is, by design, not 'Privacy-Preserving', but only 'as Privacy-Preserving as we can be, with these time constraints'.
Why does it matter?
The difference between "private" and "as private as possible" is not small, no matter how tiny it is: it is the difference between a solution that respects your privacy, and a solution that doesn't. While I can understand DP-3T and its interesting properties as an academic project, it is, IMO, a dangerous assumption to think that, because this is the best someone has came up to, that it is good enough for us, and that we should adopt it. In fact, my belief is that, since DP-3T is the best we aim to be able to achieve during this outbreak, it should not be used. On the other hand, this can and should be used as a learning experience, proof that there is a need to serious public investment on the development of real Privacy-Preserving technologies, of which anonymous communication systems are just an example.
What could have been
This article is long enough already, and I could go on and on about what can be done, if the serious effort is made to make it happen. The first paper I wrote about GNUnet was more than 15 years ago: since then many things have happened, extraordinary developments in many technological fields, a decade and half has passed... but GNUnet seems to me as being still the most promising privacy-centric project out there, and, quite unfortunately, it is still in an early alpha stage. The latest incarnation of its website has a tagline that is quite fitting for this article: "The Internet of tomorrow needs GNUnet today". In 2020, technology failed us in many ways: when a worldwide event like COVID-19 hit, we searched for technological solutions that still did not exist. 2020 was tomorrow, and we did not have GNUnet (or any other solution of choice -- take your pick, there is plenty around to do). My biggest fear on this subject is not to see solutions like DP-3T (or worse) being adopted, affecting the privacy of real lives, real people. My biggest fear that we will step out of the current sittuation, and decide not to learn from the evidences of past mistakes. Let's build the Internet of tomorrow, now.
tags: en, DP-3T, COVID-19, privacy, tracking, tracing, localization, PEPP-PT, gnunet
multi-aspell: a treat for alpine users
Probably more useful to users of tilde.pt, but maybe others of the tildeverse who speak more than one language and use alpine as a mail client, today wrote a very small shell script called multi-aspell.
multi-aspell is an helper script that shows you a list of (pre-defined)
language options to run aspell with.
It was written with the purpose of replacing the aspell invocation from alpine, in order to let you choose which language you want your e-mail to have its spell checked (useful if you're used to write mails in more than one language).
Now, before sending an email, alpine will ask me wether I want to spell check it in Portuguese or English, and then use that language to check the e-mail with.
Of course, comments, issues, patches or feature requests are more than welcome. Enjoy!
tags: pine, alpine, tilde.pt, tilde, tildeverse, aspell, multi-aspell, en
From ~marado to @marado
Speaking yesterday with someone about tilde.pt, which he found out about due to my contributions to botany, it took me a while but I did realize that there is a generational issue recognizing a ~, or, in particular, recognizing it as a way to refer to someone.
Once upon a time, before @username was the common way to refer to a person (who
came with that first? twitter?), ~username was so. UNIX users will still be
probably used to do things like cd ~ to go to their $HOME, or even ~user
to refer to some other person's home. But I do not think that's where the most
common ~ recognition comes from: instead, what people will most remember is
the number of websites of "white pages" (as some other person refered about
them to me as), that had, as an address, http://institution/~username.
So, where does this ~ come from? Well, there was a time where every machine
connected to the web was more or less expected to have Apache's
httpd running, and it had a useful module, called
mod_userdir. UserDir actually was inherited: Apache's httpd started in 1995
as a continuation of the NCSA HTTPd webserver, and NCSA not only had the
UserDir directive, it was actually active by
default.
What does all this means? Well, it means that, by default, UNIX machines with a
webserver running would probably have NCSA or later Apache's httpd, which, by
default, would be allowing each of that server's users to have their own
website, at the address http://server.address/~username , and to have something
in there they'd just have to put some html pages into their public_html
directory.
tags: history, tilde, UNIX, username, apache, httpd, userdir, en
My very first blog post... again
This is not my first blog, so it is also not my first blog post, but... it is the first post of my new blog, and, well, it is costumary to make an hello world sort of blog post, so here's mine.
I am not a fan of blogs: I never was, even when I maintained quite regularly a personal blog in the past. But it seems that blogs are the new trend on the tildeverse, and, well, I guess I'll stop tild'ing like it was the nineties, and get do it like it was the 2000's again.
Do not expect this to be updated very often... or at all. But... well, not even I know exactly what I expect this tilde of mine to become, so I guess we'll find out together!
tags: blog, hello-world, en